

ESPnet 導入編
概要
ESPnet を使うために CUDA 系を導入 記事の続きです
| 環境 | Windows10 @ WSL2 + Ubuntu 22.04 |
| グラボ | GTX 1060 6G 😭 |
1. git clone で ESPNet を DL
# cd ~ または cd $HOME でホームディレクトリに移動のち
# git で配布元から構成を保ったままDL
cd ~
git clone https://github.com/espnet/espnet執筆時点の容量は約 1GB で、処理DL完了まで少し時間がかかります。
💡 バックアップ小テクニック
本筋とは関係ありませんが、
git でコピーDLしてきた espnet ディレクトリ(フォルダ)を zip -r espnet.zip espnet コマンドで、zipに圧縮したのち、
Windows 側にバックアップしておくと、今後やり直す機会があった場合の時短となります。
解凍展開する場合は unzip espnet.zip です。
コマンドがなければ各、以下でインストールしてください
sudo apt install unzip圧縮sudo apt install zip解凍
まだunzipが入っていない場合、
「zip入れたけどunzipも一緒に入れとく?」と訊ねられるかもしれません。
今後もし 最初(ESPnetのDL)からやり直したくなった場合は、
rm -r -f espnet/ で ESPnet のディレクトリを一括削除しておき、
git clone https://github.com/espnet/espnet で再びDLしなすか
或いは、今述べたバックアップ用 .zip を解凍する感じになります
( 自分は試行錯誤してたので、後者で取り廻しています )
2. miniconda で内部環境を構築
ESPnet - Installation
https://espnet.github.io/espnet/installation.html#step-2-installation-espnet
具体的に何をどういう理由でやっているのか、自分でもちょっと知識が浅く及ばないのですが、
「"ESPnet が使う専用のPython環境" を内部にこさえる目的」があるのかなと思います。
※ 本ケースでは ↑ 公式解説で示された選択肢の中から、以下を選んだ前提で話を進めていきます
- 3.Setup Python environment
- Option A) Setup conda environment
# ホームディレクトリ配下の espnet/tools ディレクトリへ移動したのち
# セットアップ用のスクリプトをオプション付きで実行
cd $HOME/espnet/tools
./setup_anaconda.sh miniconda espnet 3.103.10 は Python のバージョンです。
公式解説は 3.8 表記ですが 今回 3.10 で試す事としました。
↑ を実行すると ログや進捗表記が表示され、1~2分ほど待たされます。
3. ESPnet の make 構築
まず最初に、以下のコマンド応答が全て正しく来るか確認してください。
ここでそれっぽいログが出てこないと、以降の工程が正常に進みません
-
nvcc -V来ない場合は CUDA のpathが通っていない可能性が高いです。
このままだと、GPUを使わないモードで進んでしまうかも?
( make に CUDA_VERSION=X.X を与える事で上手く進められる可能性もありますが、憶測の範疇です ) -
make --version
来ない場合はsudo apt install -y makeでインストールしてください -
gcc --version
来ない場合はsudo apt install -y gccでインストールしてください
上のコマンドは問題なさそうですか?
ほなら、1つ前のセットアップ項目で下ごしらえした ESPnet 環境を、以下の make コマンドでコンパイルします。
別途コマンドでオプションを付けられますが、今回は未設定で進めます
cd $HOME/espnet/tools
make自環境で通した時のログ抜粋
CUDA_VERSION=11.7
PYTHON=/home/higehito/espnet/tools/miniconda/envs/espnet/bin/python3
PYTHON_VERSION=Python 3.10.11
USE_CONDA=1
TH_VERSION=1.13.1
WITH_OMP=ON
. ./activate_python.sh && python3 -m pip install packaging
完了後、 [x] マークの付いた表が出てきます。
[x] の付いた部分が、ESPNet内の環境で利用可能(導入済)と判断された物ぽいです。
逆に空白部分 [ ] は未導入。
この時点で足りないものがあれば、後述 5. の 仮想環境 へ追加する感じになります。
4. インストールチェック
ひとまず ESPNet の基本的な環境が出来上がりました。
ESPNet 環境内では何がインストール,認識されているか、以下で確認できます。
cd $HOME/espnet/tools
bash -c ". ./activate_python.sh; . ./extra_path.sh; python3 check_install.py"ここで出力されるログは、前項の make 処理完了後に出てくる [x] の表と同じです
5. 仮想環境の触り方 (or アクティベート)
ESPNet 環境を弄るには、ESPNet 専用の環境(仮想環境)に一度入る必要があり、
これを アクティベート と表現するようです。
ただ、公式側で示されている方法 が、
仮想環境へは直接入らず、bash -c で分身(?)を仮想環境へ送り込んでコマンド実行
的な、間接実行の振る舞いでした。
以下、コマンド紹介を踏まえた実例です。
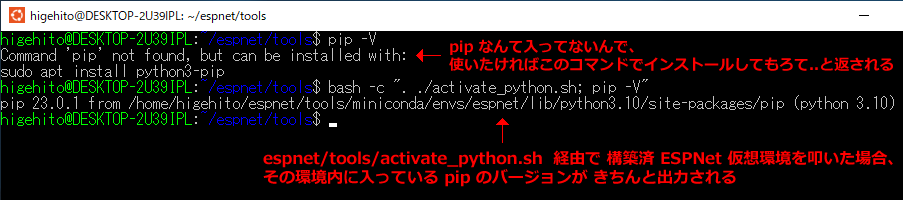
平時の環境では pip を(まだ)インストールしていなかったので、pip -V では応答しません。
ですが、miniconda と make を使って構築した EPSNet 環境内では pip がインストールされた状態なので、
/espnet/tools/ 配下で bash -c ". ./activate_python.sh; pip -V" を実行すると、
ESPNet 環境下の pip バージョンが出力されます。
espnet/tools/activate_python.sh を介して、任意コマンドを仮想環境内で実行する みたいな印象ですね。
実際に仮想環境へ入る
先程は bash -c で分身を飛ばす方法でしたが、直接潜り込みたい(アクティベートしたい)場合は以下コマンドから。
( ↓ 先頭のドット . を忘れずに )
. $HOME/espnet/tools/activate_python.sh
実行すると、ESPNet の環境へ入り、先頭に仮想環境名 (espnet) の文言が付きます。
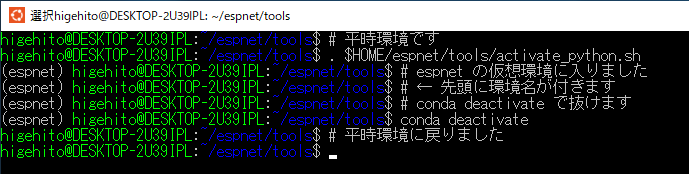
仮想環境から抜ける
抜け出る時は conda deactivate で戻れるようです。
6. PyOpenJTalk 導入
日本語対応の TTS (Text To Speech) をやりたいので、
必須とされている PyOpenJTalk を、ESPNet用仮想環境内に向けてインストールします。
公式の導入説明 では、御膳立て用のスクリプトが用意されているので、これを実行。
cd $HOME/espnet/tools
bash -c ". activate_python.sh; ./installers/install_pyopenjtalk.sh"この時、インストールされた PyOpenJTalk のバージョンは 0.3.0 でした。
7. ESPNet 環境内で PyTorch 関連を確認
ESPNet環境をアクティベートしていることが前提
. $HOME/espnet/tools/activate_python.shpython コマンドで Python を実行しておき、
>>> の入力状態になったら、以下を一行ずつコピペで実行
import torch
print(torch.__version__)※ 終了するには exit() を入力実行して Python から抜けてください。
これで出力された物が
1.13.1+cu113 のような表記でなく、
1.13.1 といった数値だけなら、CUDA関連?を認識できていない可能性が高いです。
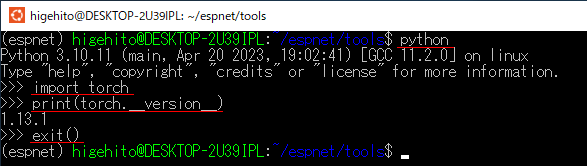
その場合は、PyTorch なるものを新しく(追加で)インストールしなおします
PyTorch 公式 https://pytorch.org/get-started/locally/ 上で、
チョイスした環境に応じて、適切なインストール用コマンドが示されます。
本環境は WSL2 + Ubuntu に加え、CUDA は 11.7 なので以下のような感じに。
( 執筆時では CUDA 12.1 が最新ですが、敢えて PyTorch 側に合わせています )

上記環境 + 執筆時点で示されたインストール用コマンドは 直接実行せず
アクティベート後(経由)の仮想環境内で送り込みます。
pip3 install torch torchvision torchaudio
なので実際は ↓ こっち ↓
# 念の為、最初に一回環境を抜ける
conda deactivate
# activate_python.sh を通して仮想環境にコマンドを流し込むイメージ
cd $HOME/espnet/tools
bash -c ". activate_python.sh; pip3 install torch torchvision torchaudio"- トラブルメモ 💦
※ アクティベート後のespnet環境内で 直接pip3 install torch torchvision torchaudioを実行したら、
インストール自体は正常に終了したものの、その後のインストールチェックでエラーを吐いてしまいました。
pip --uninstallを駆使して torch 系を複数アンインストール後、
今度は上記のbash -cとactivate_python.shファイル経由のコマンドで再インストールを行った所、
正常にインストールチェックが通っています。
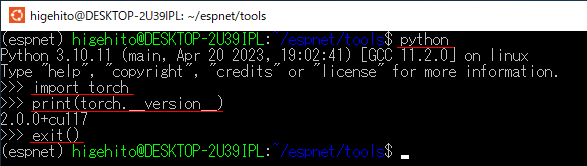
以下は、アクティベート後に torch 系をインストールし終えた状態の確認画像です。
先程の画像と結果が異なり、CUDA を対応認識してるっぽい雰囲気が伺えます
! この時点での容量
Windows 側のアプリで Ubuntu の容量を見ると 36.1 GB となっていました。
( 実際はホームディレクトリに CUDA 系のインストールパッケージを置いてるので、そこを削れば数GB減らせそうですが )
8. 実際にTTSを試してみる
実際に、テキスト経由で発話させた .wav ファイルを書き出してみます。
後述の Python ソースコードを "任意名.py" で作成し、ホームディレクトリへ配置。
仮想環境に入っている状態で python 任意名.py として実行
実行すると、初回は学習済みモデルのDL処理で暫く待たされたのち ( 15分前後? )
ホームディレクトリに .wav が書き出されます。
二回目からの実行は、既にモデルが内部にDL展開されているのですぐ終わると思います。
自環境では以下のようなログも出ましたが、処理を妨げる露骨なエラーではないのかな?と感じます
/home/higehito/espnet/espnet2/gan_tts/vits/monotonic_align/init.py:19: UserWarning: Cython version is not available.
Fallback to 'EXPERIMETAL' numba version.
If you want to use the cython version, please build it as follows:cd espnet2/gan_tts/vits/monotonic_align; python setup.py build_ext --inplace
A. 書き出しシンプル CPU実行版
ESPNet > espnet_model_zoo > README.md > TTS
# 環境アクティベート後に実行
import soundfile
from espnet2.bin.tts_inference import Text2Speech
model_name = "kan-bayashi/tsukuyomi_full_band_vits_prosody"
text2speech = Text2Speech.from_pretrained(model_name)
speech = text2speech("おはようございます、気持ちの良い朝ですね")["wav"]
soundfile.write("test_simple.wav", speech.numpy(), text2speech.fs, "PCM_16")- 補足
model_name の値は、ESPnet Model Zoo に対応した、
事前学習済みモデルに紐づけられた独自の名前,タグです。
以下のリストから選べますが、本ケースでは tts & jp 対応の物じゃないとダメかもしれません。
( 分かりにくいですが、右側へもスクロールでき、そこに項目があります )
https://github.com/espnet/espnet_model_zoo/blob/master/espnet_model_zoo/table.csv
B. 書き出し GPU アプローチ版
参考 : Zenn - ESPNet2 で日本語 TTS(Text-to-speech)するメモ (Windows でも動くよ)
https://zenn.dev/syoyo/articles/8b533927189bde
https://colab.research.google.com/github/espnet/notebook/blob/master/espnet2_tts_realtime_demo.ipynb
# 環境アクティベート後に実行
import time
import torch
import soundfile as sf
from espnet2.bin.tts_inference import Text2Speech
from espnet2.utils.types import str_or_none
lang = 'Japanese'
# つくよみちゃん なるものを指定
tag = 'kan-bayashi/tsukuyomi_full_band_vits_prosody'
# ボコーダー なるものは未指定
vocoder_tag = 'none'
# Use device="cuda" if you have GPU
text2speech = Text2Speech.from_pretrained(
model_tag=str_or_none(tag),
# 今後、独自の学習モデル(.pth)を使いたい場合、
# ↑ の model_tag は無効化し、
# ↓ 代わりに使いたい model_file パスを指定すればOK
#model_file='espnet/egs2/キャラ名/tts1/exp/tts_full_band_vits/ほにゃららepoch.pth',
vocoder_tag=str_or_none(vocoder_tag),
# GPU(というかcuda)を認識、使える場合は ="cuda" を指定できる。
# 使えない場合は ="cpu" となる
device="cuda",
# Only for Tacotron 2 & Transformer
threshold=0.5,
# Only for Tacotron 2
minlenratio=0.0,
maxlenratio=10.0,
use_att_constraint=False,
backward_window=1,
forward_window=3,
# Only for FastSpeech & FastSpeech2 & VITS
speed_control_alpha=1.0,
# Only for VITS
noise_scale=0.333,
noise_scale_dur=0.333,
)
print("text2speech 構築")
x = "こんばんは、陽もすっかり沈んでしまいましたね"
ts = text2speech(x)
print(ts)
# synthesis
with torch.no_grad():
start = time.time()
wav = text2speech(x)["wav"]
rtf = (time.time() - start) / (len(wav) / text2speech.fs)
print(f"RTF = {rtf:5f}")
wavdata = wav.view(-1).cpu().numpy()
samplerate=text2speech.fs
sf.write('test_tts.wav', wavdata, samplerate, subtype='PCM_24')-
トラブルメモ
device="cuda"で GPUを使えますが、ここでもし CUDA系を導入済みにもかかわらず ↓Could not load library libcudnn_cnn_infer.so.8. Error: libcuda.so: cannot open shared object file: No such file or directory Aborted↑ 的なエラーが出ると、ライブラリへのパスが通っていない可能性があるのかなと。
参考 : Qiita > WSL2で libcuda.so: cannot open shared object fileになる -
余談
ちなみに、この時DLされたファイルは環境内のライブラリ中にDL & 展開されて使われる模様。
/espnet/tools/miniconda/envs/espnet/lib/python3.10/site-packages/espnet_model_zoo/[ハッシュ]/
( 直接触らないほうが絶対良さそう )
問題なく実行出来れば、指定名の .wav ファイル 🔊 が書き出されます。
💡 モデルバックアップ利用小テクニック
今後再び ESPNet を最初から構築した場合、TTS利用でDLした学習済みモデルも消えてしまいます。
動作確認の為?とはいえ、また初回DLで待たされるのが嫌な場合は、
あらかじめDLした(バックアップ先から持ってきた)対応モデルを呼び出す事も出来ます。
以下の表、右側のURLからモデルをDLできます (分かりにくいですが、横にもスクロールできる)
https://github.com/espnet/espnet_model_zoo/blob/master/espnet_model_zoo/table.csv
例えば 日本語対応 つくよみちゃん TTS 対応の "kan-bayashi/tsukuyomi_full_band_vits_prosody" モデルの場合、
https://zenodo.org/record/5521446/files/tts_finetune_full_band_jsut_vits_raw_phn_jaconv_pyopenjtalk_prosody_latest.zip?download=1
でDLした .zip をそのまま任意場所へ配置したのち、以下のような体裁で試せます。
( 本例では /espnet/local_zoo_models/ファイル名.zip の独自ディレクトリ内としました )
下記の .py 自体は ホームディレクトリ上での配置,実行としています。
import soundfile
from espnet2.bin.tts_inference import Text2Speech
zip_file_name = "tts_finetune_full_band_jsut_vits_raw_phn_jaconv_pyopenjtalk_prosody_latest.zip"
# 相対パスで指定
model_path = ("./espnet/local_zoo_models/" + zip_file_name)
speech = text2speech("ローカルモデルファイルの直接指定も一応可能です")["wav"]
soundfile.write("test_local_zoo_model.wav", speech.numpy(), text2speech.fs, "PCM_16")